- Published on
Road to petaflop
- Authors

- Name
- Jack Youstra
- @jackyoustra
Introduction
I just got my 5090 after seeing that I could get a petaflop of fp4 compute! I've been wanting to use it for a while.

There's quite a few steps in order to use the full petaflop of compute:
- Quantize in tensorrt-llm
- Run in tensorrt (chose not to - I prefer sglang myself!)
- Run in sglang
We'll be going through each.
Theory
The nvfp4 format
There's a nvidia blog post here that explains the nvfp4 format; you can also look at technical docs if need be. The first thing to notice is nvfp4 is not IEEE fp4. I had claude cook up a visualization to show you how it works:
Dual-Scaling Mechanism
NVFP4 in Matrix Multiplication
The GPU's Blackwell Tensor Cores handle dequantization in hardware:
RTX 5090 Performance Impact
Compute
Memory
The key point to realize is that this patch is a little more complicated than most quants: you have a weight quantization, a fp8 ublock scale, and a full-tensor scale.
Quantize in tensorrt-llm
There are two ways to quantize to nvfp4: llm-compressor by the famous quantizer NeuralMagic and tensorrt-llm's child project TensorRT-Model-Optimizer (colloqually known as 'modelopt') by nvidia. The community is moving to modelopt, so that's the solution we'll use.
You quantize something (for now) by installing the project and using either the example_hf.sh script in the examples/llm_ptq folder or by running the python script yourself. For our purposes, we'll be running scripts/huggingface_example.sh --qformat nvfp4 --export_fmt hf --model meta-llama/Llama-3.1-8B-Instruct.
Getting it to run in sglang sometimes can have trouble picking up the scale factors - it differs based on engine whether it expects qkv scale to be fused or not. I fixed this (I hope) and so we proceed.
Run in sglang
So, we've got our nvfp4 quantized model. Let's just run it! As always on this blog, we hope for things to work on the first try.
(sglang) jack@Chimaera:~/llm/sglang$ python -m sglang.launch_server --quantization modelopt_fp4 --model /home/jack/llm/tensorrt-model-optimizer/TensorRT-Model-Optimizer/examples/llm_ptq/saved_models_Llama-3_1-8B-Instruct_nvfp4_hf/
[2025-06-05 17:27:17] server_args=ServerArgs(model_path='/home/jack/llm/tensorrt-model-optimizer/TensorRT-Model-Optimizer/examples/llm_ptq/saved_models_Llama-3_1-8B-Instruct_nvfp4_hf/', tokenizer_path='/home/jack/llm/tensorrt-model-optimizer/TensorRT-Model-Optimizer/examples/llm_ptq/saved_models_Llama-3_1-8B-Instruct_nvfp4_hf/', tokenizer_mode='auto', skip_tokenizer_init=False, load_format='auto', trust_remote_code=False, dtype='auto', kv_cache_dtype='auto', quantization='modelopt_fp4', quantization_param_path=None, context_length=None, device='cuda', served_model_name='/home/jack/llm/tensorrt-model-optimizer/TensorRT-Model-Optimizer/examples/llm_ptq/saved_models_Llama-3_1-8B-Instruct_nvfp4_hf/', chat_template=None, completion_template=None, is_embedding=False, enable_multimodal=None, revision=None, impl='auto', host='127.0.0.1', port=30000, mem_fraction_static=0.88, max_running_requests=None, max_total_tokens=None, chunked_prefill_size=8192, max_prefill_tokens=16384, schedule_policy='fcfs', schedule_conservativeness=1.0, cpu_offload_gb=0, page_size=1, tp_size=1, pp_size=1, max_micro_batch_size=None, stream_interval=1, stream_output=False, random_seed=52337469, constrained_json_whitespace_pattern=None, watchdog_timeout=300, dist_timeout=None, download_dir=None, base_gpu_id=0, gpu_id_step=1, log_level='info', log_level_http=None, log_requests=False, log_requests_level=0, show_time_cost=False, enable_metrics=False, bucket_time_to_first_token=None, bucket_e2e_request_latency=None, bucket_inter_token_latency=None, collect_tokens_histogram=False, decode_log_interval=40, enable_request_time_stats_logging=False, kv_events_config=None, api_key=None, file_storage_path='sglang_storage', enable_cache_report=False, reasoning_parser=None, dp_size=1, load_balance_method='round_robin', ep_size=1, dist_init_addr=None, nnodes=1, node_rank=0, json_model_override_args='{}', preferred_sampling_params=None, lora_paths=None, max_loras_per_batch=8, lora_backend='triton', attention_backend=None, sampling_backend='flashinfer', grammar_backend='xgrammar', speculative_algorithm=None, speculative_draft_model_path=None, speculative_num_steps=None, speculative_eagle_topk=None, speculative_num_draft_tokens=None, speculative_accept_threshold_single=1.0, speculative_accept_threshold_acc=1.0, speculative_token_map=None, enable_double_sparsity=False, ds_channel_config_path=None, ds_heavy_channel_num=32, ds_heavy_token_num=256, ds_heavy_channel_type='qk', ds_sparse_decode_threshold=4096, disable_radix_cache=False, disable_cuda_graph=False, disable_cuda_graph_padding=False, enable_nccl_nvls=False, enable_tokenizer_batch_encode=False, disable_outlines_disk_cache=False, disable_custom_all_reduce=False, disable_overlap_schedule=False, enable_mixed_chunk=False, enable_dp_attention=False, enable_dp_lm_head=False, enable_two_batch_overlap=False, enable_ep_moe=False, enable_deepep_moe=False, deepep_mode='auto', ep_num_redundant_experts=0, ep_dispatch_algorithm='static', init_expert_location='trivial', enable_eplb=False, eplb_algorithm='auto', eplb_rebalance_num_iterations=1000, expert_distribution_recorder_mode=None, expert_distribution_recorder_buffer_size=1000, enable_expert_distribution_metrics=False, deepep_config=None, enable_torch_compile=False, torch_compile_max_bs=32, cuda_graph_max_bs=None, cuda_graph_bs=None, torchao_config='', enable_nan_detection=False, enable_p2p_check=False, triton_attention_reduce_in_fp32=False, triton_attention_num_kv_splits=8, num_continuous_decode_steps=1, delete_ckpt_after_loading=False, enable_memory_saver=False, allow_auto_truncate=False, enable_custom_logit_processor=False, tool_call_parser=None, enable_hierarchical_cache=False, hicache_ratio=2.0, hicache_size=0, hicache_write_policy='write_through_selective', flashinfer_mla_disable_ragged=False, warmups=None, moe_dense_tp_size=None, disable_shared_experts_fusion=False, disable_chunked_prefix_cache=False, disable_fast_image_processor=False, mm_attention_backend=None, debug_tensor_dump_output_folder=None, debug_tensor_dump_input_file=None, debug_tensor_dump_inject=False, disaggregation_mode='null', disaggregation_bootstrap_port=8998, disaggregation_transfer_backend='mooncake', disaggregation_ib_device=None, pdlb_url=None)
[2025-06-05 17:27:17] modelopt_fp4 quantization is not fully optimized yet. The speed can be slower than non-quantized models.
[2025-06-05 17:27:22] modelopt_fp4 quantization is not fully optimized yet. The speed can be slower than non-quantized models.
[2025-06-05 17:27:23] modelopt_fp4 quantization is not fully optimized yet. The speed can be slower than non-quantized models.
[2025-06-05 17:27:23] Attention backend not set. Use flashinfer backend by default.
[2025-06-05 17:27:23] Init torch distributed begin.
[W605 17:27:23.294688919 ProcessGroupNCCL.cpp:978] Warning: TORCH_NCCL_AVOID_RECORD_STREAMS is the default now, this environment variable is thus deprecated. (function operator())
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[2025-06-05 17:27:23] Init torch distributed ends. mem usage=0.00 GB
[2025-06-05 17:27:24] Load weight begin. avail mem=30.02 GB
[2025-06-05 17:27:24] Detected nvfp4 checkpoint. Please note that the format is experimental and subject to change.
Loading safetensors checkpoint shards: 0% Completed | 0/2 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 50% Completed | 1/2 [00:00<00:00, 1.16it/s]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:03<00:00, 1.98s/it]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:03<00:00, 1.81s/it]
[2025-06-05 17:27:29] Load weight end. type=LlamaForCausalLM, dtype=torch.bfloat16, avail mem=23.92 GB, mem usage=6.11 GB.
[2025-06-05 17:29:50] KV Cache is allocated. #tokens: 166318, K size: 10.15 GB, V size: 10.15 GB
[2025-06-05 17:29:50] Memory pool end. avail mem=1.50 GB
2025-06-05 17:29:56,090 - INFO - flashinfer.jit: Prebuilt kernels not found, using JIT backend
[2025-06-05 17:29:56] Capture cuda graph begin. This can take up to several minutes. avail mem=0.98 GB
[2025-06-05 17:29:56] Capture cuda graph bs [1, 2, 4, 8, 16, 24, 32, 40, 48, 56, 64, 72, 80, 88, 96, 104, 112, 120, 128, 136, 144, 152, 160]
Capturing batches (avail_mem=0.75 GB): 0%| | 0/23 [00:00<?, ?it/s]2025-06-05 17:30:41,383 - INFO - flashinfer.jit: Loading JIT ops: batch_decode_with_kv_cache_dtype_q_bf16_dtype_kv_bf16_dtype_o_bf16_dtype_idx_i32_head_dim_qk_128_head_dim_vo_128_posenc_0_use_swa_False_use_logits_cap_False
2025-06-05 17:30:55,853 - INFO - flashinfer.jit: Finished loading JIT ops: batch_decode_with_kv_cache_dtype_q_bf16_dtype_kv_bf16_dtype_o_bf16_dtype_idx_i32_head_dim_qk_128_head_dim_vo_128_posenc_0_use_swa_False_use_logits_cap_False
Capturing batches (avail_mem=0.75 GB): 0%| | 0/23 [00:25<?, ?it/s]
[2025-06-05 17:30:55] Scheduler hit an exception: Traceback (most recent call last):
File "/home/jack/llm/sglang/python/sglang/srt/model_executor/cuda_graph_runner.py", line 303, in __init__
self.capture()
File "/home/jack/llm/sglang/python/sglang/srt/model_executor/cuda_graph_runner.py", line 389, in capture
) = self.capture_one_batch_size(bs, forward)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/jack/llm/sglang/python/sglang/srt/model_executor/cuda_graph_runner.py", line 514, in capture_one_batch_size
run_once()
File "/home/jack/llm/sglang/python/sglang/srt/model_executor/cuda_graph_runner.py", line 502, in run_once
logits_output_or_pp_proxy_tensors = forward(
^^^^^^^^
File "/home/jack/llm/sglang/.venv/lib/python3.12/site-packages/torch/utils/_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/home/jack/llm/sglang/python/sglang/srt/models/llama.py", line 457, in forward
hidden_states = self.model(
^^^^^^^^^^^
File "/home/jack/llm/sglang/.venv/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1767, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/jack/llm/sglang/.venv/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1778, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/jack/llm/sglang/python/sglang/srt/models/llama.py", line 334, in forward
hidden_states, residual = layer(
^^^^^^
File "/home/jack/llm/sglang/.venv/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1767, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/jack/llm/sglang/.venv/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1778, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/jack/llm/sglang/python/sglang/srt/models/llama.py", line 258, in forward
hidden_states = self.self_attn(
^^^^^^^^^^^^^^^
File "/home/jack/llm/sglang/.venv/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1767, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/jack/llm/sglang/.venv/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1778, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/jack/llm/sglang/python/sglang/srt/models/llama.py", line 186, in forward
qkv, _ = self.qkv_proj(hidden_states)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/jack/llm/sglang/.venv/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1767, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/jack/llm/sglang/.venv/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1778, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/jack/llm/sglang/python/sglang/srt/layers/linear.py", line 445, in forward
output_parallel = self.quant_method.apply(self, input_, bias)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/jack/llm/sglang/python/sglang/srt/layers/quantization/modelopt_quant.py", line 453, in apply
out = cutlass_scaled_fp4_mm(
^^^^^^^^^^^^^^^^^^^^^^
File "/home/jack/llm/sglang/.venv/lib/python3.12/site-packages/sgl_kernel/gemm.py", line 143, in cutlass_scaled_fp4_mm
torch.ops.sgl_kernel.cutlass_scaled_fp4_mm.default(
File "/home/jack/llm/sglang/.venv/lib/python3.12/site-packages/torch/_ops.py", line 806, in __call__
return self._op(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: Error Internal
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/jack/llm/sglang/python/sglang/srt/managers/scheduler.py", line 2478, in run_scheduler_process
scheduler = Scheduler(server_args, port_args, gpu_id, tp_rank, pp_rank, dp_rank)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/jack/llm/sglang/python/sglang/srt/managers/scheduler.py", line 281, in __init__
self.tp_worker = TpWorkerClass(
^^^^^^^^^^^^^^
File "/home/jack/llm/sglang/python/sglang/srt/managers/tp_worker_overlap_thread.py", line 64, in __init__
self.worker = TpModelWorker(
^^^^^^^^^^^^^^
File "/home/jack/llm/sglang/python/sglang/srt/managers/tp_worker.py", line 78, in __init__
self.model_runner = ModelRunner(
^^^^^^^^^^^^
File "/home/jack/llm/sglang/python/sglang/srt/model_executor/model_runner.py", line 230, in __init__
self.initialize(min_per_gpu_memory)
File "/home/jack/llm/sglang/python/sglang/srt/model_executor/model_runner.py", line 305, in initialize
self.init_cuda_graphs()
File "/home/jack/llm/sglang/python/sglang/srt/model_executor/model_runner.py", line 1125, in init_cuda_graphs
self.cuda_graph_runner = CudaGraphRunner(self)
^^^^^^^^^^^^^^^^^^^^^
File "/home/jack/llm/sglang/python/sglang/srt/model_executor/cuda_graph_runner.py", line 305, in __init__
raise Exception(
Exception: Capture CUDA graph failed: Error Internal
Possible solutions:
1. set --mem-fraction-static to a smaller value (e.g., 0.8 or 0.7)
2. set --cuda-graph-max-bs to a smaller value (e.g., 16)
3. disable torch compile by not using --enable-torch-compile
4. disable CUDA graph by --disable-cuda-graph. (Not recommended. Huge performance loss)
Open an issue on GitHub https://github.com/sgl-project/sglang/issues/new/choose
As often on this blog, we are disappointed.
The line that sticks out is RuntimeError: Error Internal. You'd think this to be a driver error, but after some googling, it turns out it's a CUTLASS error. We grep the sglang codebase (+ dependencies) and find in cutlass.h:
case cutlass::Status::kErrorInternal:
return "Error Internal";
what gives?
Iterating on this will quickly become tiresome - it takes a few minutes to run a single test. A quicker way is to just test the failing function directly. We can make a toy script to test out this behavior without having to load a full model:
#!/usr/bin/env python3
import torch
import ctypes
import os
# Load CUDA runtime library
cuda = ctypes.CDLL("/usr/local/cuda/lib64/libcudart.so")
# Define cudaGetErrorString
cuda.cudaGetErrorString.restype = ctypes.c_char_p
cuda.cudaGetErrorString.argtypes = [ctypes.c_int]
from sgl_kernel import cutlass_scaled_fp4_mm, scaled_fp4_quant
device = "cuda"
dtype = torch.bfloat16
t = 128
m, n, k = t, t, t
a = torch.randn(m, k, dtype=dtype, device=device) * 0.1
b = torch.randn(k, n, dtype=dtype, device=device) * 0.1
# Quantize
input_scale = torch.tensor(1.0, dtype=torch.float32, device=device)
a_fp4, a_scale = scaled_fp4_quant(a, 1 / input_scale)
b_fp4, b_scale = scaled_fp4_quant(b, 1 / input_scale)
alpha = torch.tensor(1.0, dtype=torch.float32, device=device)
# Clear any existing errors
cuda.cudaGetLastError()
print("Calling FP4 GEMM...")
try:
result = cutlass_scaled_fp4_mm(a_fp4, b_fp4, a_scale, b_scale, alpha, dtype)
except Exception as e:
print(f"Python exception: {e}")
# Check CUDA error
error_code = cuda.cudaGetLastError()
if error_code != 0:
error_string = cuda.cudaGetErrorString(error_code)
print(f"CUDA error code: {error_code}")
print(f"CUDA error string: {error_string.decode('utf-8')}")
# Also check with PyTorch's error checking
try:
torch.cuda.synchronize()
except Exception as sync_e:
print(f"Sync error: {sync_e}")
This reproduces the error in the cutlass_scaled_fp4_mm function.
Now we have to figure out what's going on. For reference, here's a link to the concerned function.
For such failures, there's a lot of available CUDA debugging tools. The relevant one to try out now is compute-sanitizer. You just run it like valgrind: shove it in front of the command you want to run.
sglangjack@Chimaera:~/llm/sglang$ /usr/local/cuda/bin/compute-sanitizer python test_cuda_error_check.py
========= COMPUTE-SANITIZER
Calling FP4 GEMM...
========= Program hit cudaErrorInvalidValue (error 1) due to "invalid argument" on CUDA API call to cudaFuncSetAttribute.
========= Saved host backtrace up to driver entry point at error
========= Host Frame: void runGemm<cutlass::bfloat16_t>(at::Tensor&, at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&, long, long, long, CUstream_st*) [0x1b1bf3] in common_ops.abi3.so
========= Host Frame: cutlass_scaled_fp4_mm_sm100a(at::Tensor&, at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&) [0x1a87cd] in common_ops.abi3.so
========= Host Frame: c10::impl::make_boxed_from_unboxed_functor<c10::impl::detail::WrapFunctionIntoRuntimeFunctor_<void (*)(at::Tensor&, at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&), void, c10::guts::typelist::typelist<at::Tensor&, at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&> >, false>::call(c10::OperatorKernel*, c10::OperatorHandle const&, c10::DispatchKeySet, std::vector<c10::IValue, std::allocator<c10::IValue> >*) [0x2129fe] in common_ops.abi3.so
========= Host Frame: torch::autograd::basicAutogradNotImplementedFallbackImpl(c10::OperatorHandle const&, c10::DispatchKeySet, std::vector<c10::IValue, std::allocator<c10::IValue> >*) [0x52f6a64] in libtorch_cpu.so
========= Host Frame: c10::Dispatcher::callBoxed(c10::OperatorHandle const&, std::vector<c10::IValue, std::allocator<c10::IValue> >*) const [clone .isra.0] [0x5af542a] in libtorch_cpu.so
========= Host Frame: torch::jit::invokeOperatorFromPython(std::vector<std::shared_ptr<torch::jit::Operator>, std::allocator<std::shared_ptr<torch::jit::Operator> > > const&, pybind11::args const&, pybind11::kwargs const&, std::optional<c10::DispatchKey>) [0x907de3] in libtorch_python.so
========= Host Frame: torch::jit::_get_operation_for_overload_or_packet(std::vector<std::shared_ptr<torch::jit::Operator>, std::allocator<std::shared_ptr<torch::jit::Operator> > > const&, c10::Symbol, pybind11::args const&, pybind11::kwargs const&, bool, std::optional<c10::DispatchKey>) [0x9081a8] in libtorch_python.so
========= Host Frame: torch::jit::initJITBindings(_object*)::{lambda(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)#2}::operator()(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) const::{lambda(pybind11::args const&, pybind11::kwargs const&)#1}::operator()(pybind11::args const&, pybind11::kwargs const&) const [0x811cdb] in libtorch_python.so
========= Host Frame: pybind11::cpp_function::initialize<torch::jit::initJITBindings(_object*)::{lambda(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)#2}::operator()(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) const::{lambda(pybind11::args const&, pybind11::kwargs const&)#1}, pybind11::object, pybind11::args const&, pybind11::kwargs const&>(torch::jit::initJITBindings(_object*)::{lambda(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)#2}::operator()(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) const::{lambda(pybind11::args const&, pybind11::kwargs const&)#1}&&, pybind11::object (*)(pybind11::args const&, pybind11::kwargs const&))::{lambda(pybind11::detail::function_call&)#1}::_FUN(pybind11::detail::function_call&) [0x81218e] in libtorch_python.so
========= Host Frame: pybind11::cpp_function::dispatcher(_object*, _object*, _object*) [0x3749b1] in libtorch_python.so
========= Host Frame: [0x18208e] in python
========= Host Frame: PyObject_Call [0x14b30b] in python
========= Host Frame: _PyEval_EvalFrameDefault [0x1db55a] in python
========= Host Frame: _PyObject_Call_Prepend [0x14a9d1] in python
========= Host Frame: [0x1a3627] in python
========= Host Frame: _PyObject_MakeTpCall [0x149184] in python
========= Host Frame: _PyEval_EvalFrameDefault [0x1d73c8] in python
========= Host Frame: PyEval_EvalCode [0x1d58ea] in python
========= Host Frame: [0x208b41] in python
========= Host Frame: [0x2b4e92] in python
========= Host Frame: _PyRun_SimpleFileObject [0x2b4bf9] in python
========= Host Frame: _PyRun_AnyFileObject [0x2b4a2e] in python
========= Host Frame: Py_RunMain [0x2bca94] in python
========= Host Frame: Py_BytesMain [0x2bc57c] in python
========= Host Frame: __libc_start_call_main in libc_start_call_main.h:58 [0x2a1c9] in libc.so.6
========= Host Frame: __libc_start_main in libc-start.c:360 [0x2a28a] in libc.so.6
========= Host Frame: _start [0x257ce4] in python
========= Host Frame: __call__ in _ops.py:806
========= Host Frame: cutlass_scaled_fp4_mm in gemm.py:143
========= Host Frame: <module> in test_cuda_error_check.py:35
=========
========= Program hit cudaErrorInvalidValue (error 1) due to "invalid argument" on CUDA API call to cudaGetLastError.
========= Saved host backtrace up to driver entry point at error
========= Host Frame: void runGemm<cutlass::bfloat16_t>(at::Tensor&, at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&, long, long, long, CUstream_st*) [0x1b21f4] in common_ops.abi3.so
========= Host Frame: cutlass_scaled_fp4_mm_sm100a(at::Tensor&, at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&) [0x1a87cd] in common_ops.abi3.so
========= Host Frame: c10::impl::make_boxed_from_unboxed_functor<c10::impl::detail::WrapFunctionIntoRuntimeFunctor_<void (*)(at::Tensor&, at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&), void, c10::guts::typelist::typelist<at::Tensor&, at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&, at::Tensor const&> >, false>::call(c10::OperatorKernel*, c10::OperatorHandle const&, c10::DispatchKeySet, std::vector<c10::IValue, std::allocator<c10::IValue> >*) [0x2129fe] in common_ops.abi3.so
========= Host Frame: torch::autograd::basicAutogradNotImplementedFallbackImpl(c10::OperatorHandle const&, c10::DispatchKeySet, std::vector<c10::IValue, std::allocator<c10::IValue> >*) [0x52f6a64] in libtorch_cpu.so
========= Host Frame: c10::Dispatcher::callBoxed(c10::OperatorHandle const&, std::vector<c10::IValue, std::allocator<c10::IValue> >*) const [clone .isra.0] [0x5af542a] in libtorch_cpu.so
========= Host Frame: torch::jit::invokeOperatorFromPython(std::vector<std::shared_ptr<torch::jit::Operator>, std::allocator<std::shared_ptr<torch::jit::Operator> > > const&, pybind11::args const&, pybind11::kwargs const&, std::optional<c10::DispatchKey>) [0x907de3] in libtorch_python.so
========= Host Frame: torch::jit::_get_operation_for_overload_or_packet(std::vector<std::shared_ptr<torch::jit::Operator>, std::allocator<std::shared_ptr<torch::jit::Operator> > > const&, c10::Symbol, pybind11::args const&, pybind11::kwargs const&, bool, std::optional<c10::DispatchKey>) [0x9081a8] in libtorch_python.so
========= Host Frame: torch::jit::initJITBindings(_object*)::{lambda(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)#2}::operator()(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) const::{lambda(pybind11::args const&, pybind11::kwargs const&)#1}::operator()(pybind11::args const&, pybind11::kwargs const&) const [0x811cdb] in libtorch_python.so
========= Host Frame: pybind11::cpp_function::initialize<torch::jit::initJITBindings(_object*)::{lambda(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)#2}::operator()(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) const::{lambda(pybind11::args const&, pybind11::kwargs const&)#1}, pybind11::object, pybind11::args const&, pybind11::kwargs const&>(torch::jit::initJITBindings(_object*)::{lambda(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)#2}::operator()(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) const::{lambda(pybind11::args const&, pybind11::kwargs const&)#1}&&, pybind11::object (*)(pybind11::args const&, pybind11::kwargs const&))::{lambda(pybind11::detail::function_call&)#1}::_FUN(pybind11::detail::function_call&) [0x81218e] in libtorch_python.so
========= Host Frame: pybind11::cpp_function::dispatcher(_object*, _object*, _object*) [0x3749b1] in libtorch_python.so
========= Host Frame: [0x18208e] in python
========= Host Frame: PyObject_Call [0x14b30b] in python
========= Host Frame: _PyEval_EvalFrameDefault [0x1db55a] in python
========= Host Frame: _PyObject_Call_Prepend [0x14a9d1] in python
========= Host Frame: [0x1a3627] in python
========= Host Frame: _PyObject_MakeTpCall [0x149184] in python
========= Host Frame: _PyEval_EvalFrameDefault [0x1d73c8] in python
========= Host Frame: PyEval_EvalCode [0x1d58ea] in python
========= Host Frame: [0x208b41] in python
========= Host Frame: [0x2b4e92] in python
========= Host Frame: _PyRun_SimpleFileObject [0x2b4bf9] in python
========= Host Frame: _PyRun_AnyFileObject [0x2b4a2e] in python
========= Host Frame: Py_RunMain [0x2bca94] in python
========= Host Frame: Py_BytesMain [0x2bc57c] in python
========= Host Frame: __libc_start_call_main in libc_start_call_main.h:58 [0x2a1c9] in libc.so.6
========= Host Frame: __libc_start_main in libc-start.c:360 [0x2a28a] in libc.so.6
========= Host Frame: _start [0x257ce4] in python
========= Host Frame: __call__ in _ops.py:806
========= Host Frame: cutlass_scaled_fp4_mm in gemm.py:143
========= Host Frame: <module> in test_cuda_error_check.py:35
=========
Python exception: Error Internal
========= ERROR SUMMARY: 2 errors
The relevant portion talks about an invalid argument in runGemm. runGemm refers to the templated cutlass method used to invoke gemm kernels, invoked here. The actual cuda API method that's failing is cudaFuncSetAttribute. We can find out precisely which one by preloading the function and hooking it and dumping the value whenever it's returned null. There may be a way to do this with gdb or cuda-gdb, but I'm unfamiliar with how to use cuda-gdb and hooking is sufficient for now.
#define _GNU_SOURCE
#include <dlfcn.h>
#include <stdio.h>
#include <cuda_runtime.h>
// Function pointer to the real cudaFuncSetAttribute
static cudaError_t (*real_cudaFuncSetAttribute)(const void*, enum cudaFuncAttribute, int) = NULL;
// Our interceptor
cudaError_t cudaFuncSetAttribute(const void* func, enum cudaFuncAttribute attr, int value) {
// Load the real function if not already loaded
if (!real_cudaFuncSetAttribute) {
real_cudaFuncSetAttribute = dlsym(RTLD_NEXT, "cudaFuncSetAttribute");
}
// Call the real function
cudaError_t result = real_cudaFuncSetAttribute(func, attr, value);
// If it failed, log it
if (result == cudaErrorInvalidValue) {
fprintf(stderr, "[INTERCEPT] cudaFuncSetAttribute failed with invalid value (attr=%d, value=%d), returning %s\n", attr, value, cudaGetErrorString(result));
return result;
}
return result;
}
and then a quick compile and run:
gcc -shared -fPIC -o cuda_ignore_setattr.so cuda_ignore_setattr.c -ldl -I/usr/local/cuda/include -L/usr/local/cuda/lib64 -lcudart
LD_PRELOAD=./cuda_ignore_setattr.so python test_fp4_minimal.py
...
[INTERCEPT] cudaFuncSetAttribute failed with invalid value (attr=8, value=217088)...
...
What's attribute 8? Looking at the docs, I eventually find it corresponds to cudaFuncAttributeMaxDynamicSharedMemorySize. For those familiar with CUDA, the use of shared corresponds to the __shared__ keyword. So we're trying to set the max shared size to 217k and failing. Looking at the 5090 docs, we find that there's 21mb available for shared memory total split over 170SMs. 21760 / 170 = 128kb per SM! Far less than the 217088 we're trying to set.
However! Not all of this is our explicit control - this is both L1 and programmable shared memory. I found a variable for this exact upper bound value. It's 101376 bytes (99 KB) on a 5090 - far smaller than 217k!
Perhaps we can try adjusting the tile shapes and see if that changes the error? But first! What tile shapes are, how CUTLASS works, and more.
CUTLASS
Writing a CUDA kernel usually revolves around the same few tricks: compute partial sums for dot products, minimizing reads to global memory, using the cache / bank coalescing efficiently, using all of the registers available, pipelining, latency hiding with swaps (and pipelining!), and more.
You can see details to this in a great blog on efficient matmul on GPUs.
On the pipelining, see this for details: https://docs.nvidia.com/cutlass/media/docs/cpp/efficient_gemm.html basically you want to double-buffer (at least) the gemm - that way you're continuously loading from global memory into shared memory for the next iteration, even as you compute the results for the current iteration.
If you've ever written any of the CUDA puzzles (or any of the variants, such as metal, wgsl, etc) you'll recognize the evolution of some of these tricks - you may also be able to spot others mentioned in places such as the flash attention blog.
What you'll realize after a while is that these patters are super repetitive, and to get a high performance kernel you'll usually want all of them (much like other parts of the inference stack! speculative decoding, sparsity, quantization, etc).
This is where CUTLASS comes in. CUTLASS is a C++ templating library that abstracts all of the details that goes into a CUDA matrix multiply kernel into a template specification. All you have to provide is (more or less) template arguments and it'll write out the CUDA kernel for you. Here is the definition of the gemm we're debugging now!
Of course, as we're seeing right now, it's hardly foolproof! This is somewhat intentional: it's a high performance library designed to obviate the need to write manual CUDA (most of the time). Get some of the details wrong and you'll get a runtime error.
Looking back to the troublesome sgl-kernel file, we can see the KernelTraits - how CUTLASS defines the tiling for the gemm:
template <>
struct KernelTraits<cutlass::half_t> {
using MmaTileShape = Shape<_256, _256, _256>;
using ClusterShape = Shape<_4, _4, _1>;
using PerSmTileShape_MNK = Shape<_128, _256, _256>;
};
template <>
struct KernelTraits<cutlass::bfloat16_t> {
using MmaTileShape = Shape<_256, _256, _256>;
using ClusterShape = Shape<_4, _4, _1>;
using PerSmTileShape_MNK = Shape<_128, _256, _256>;
};
The way GEMM works with CUTLASS is by tiling the matrices into smaller chunks and then performing the matrix multiplication on each chunk. The details are in the CUTLASS readme and tutorial that I HIGHLY recommend reading, but we'll quickly go through it for now.
The heart of LLMs are huge matrix multiplies - for an example look at a single attention head from nanogpt. For a sense of scale, the matricies concerned in this example to compute the attention query of a single head of nanoGPT are only is shape . Storing just the the input matricies in bf16 would take bytes already several times what we can store in our L1 cache!
The way we can use all of our compute without being bottlenecked by waiting on main memory is by tiling the matricies. Instead of computing the full matrix multiply all at once, we can break the output matrix into smaller chunks and assign each thread block
a section of the output matrix. For example, if our thread block has to compute a section of the output matrix, it only needs to load the of the first matrix and the whole of the second matrix, bringing our total memory footprint to bytes. This is still too big, so we take it one step further: we only load chunks of each input and output matrix and accumulate partial sums.
Our output matrix is , so our overall storage footprint is bytes. Me being lazy for the purposes of this blog post, a viable chunk would be , which would be bytes, well within our L1 limit.
Realistically the matrix sizes we'll be working with would be much, much larger. We have to write back partial sums to main memory and accumulate them, but the idea is the same - whenever you run out of memory, just chunk along whatever axis is too large.1
There's one more detail: If you notice our above outline has "load, work, store" - this is quite inefficient! You want to pipeline the computation so you're using both all of your compute units (VALUs) as well as all of your memory controller bandwidth at once.
CUTLASS is nice because all you have to do is specify all of the above hyperparameters and it'll write out the CUDA kernel for you - no need to actually slam it out yourself! Only if you have something particularly baroque or irregular would you need to write your own kernel, even something like a new sparsity pattern you should be able to graft on to the existing CUTLASS library.
There's so much more to how to tune these values, read the JAX scaling book and the CUTLASS tutorial / guide for more details.
Building sglang
Managing builds was a surprisingly troublesome part of this project. I'll go through the process of setting up a build system that's both fast and resilient.
Problems with memory
There's a good diagram of the CUDA build taxonomy here. Here's a diagram of the build process that occurs when invoking nvcc: the compiler driver2 for cuda: 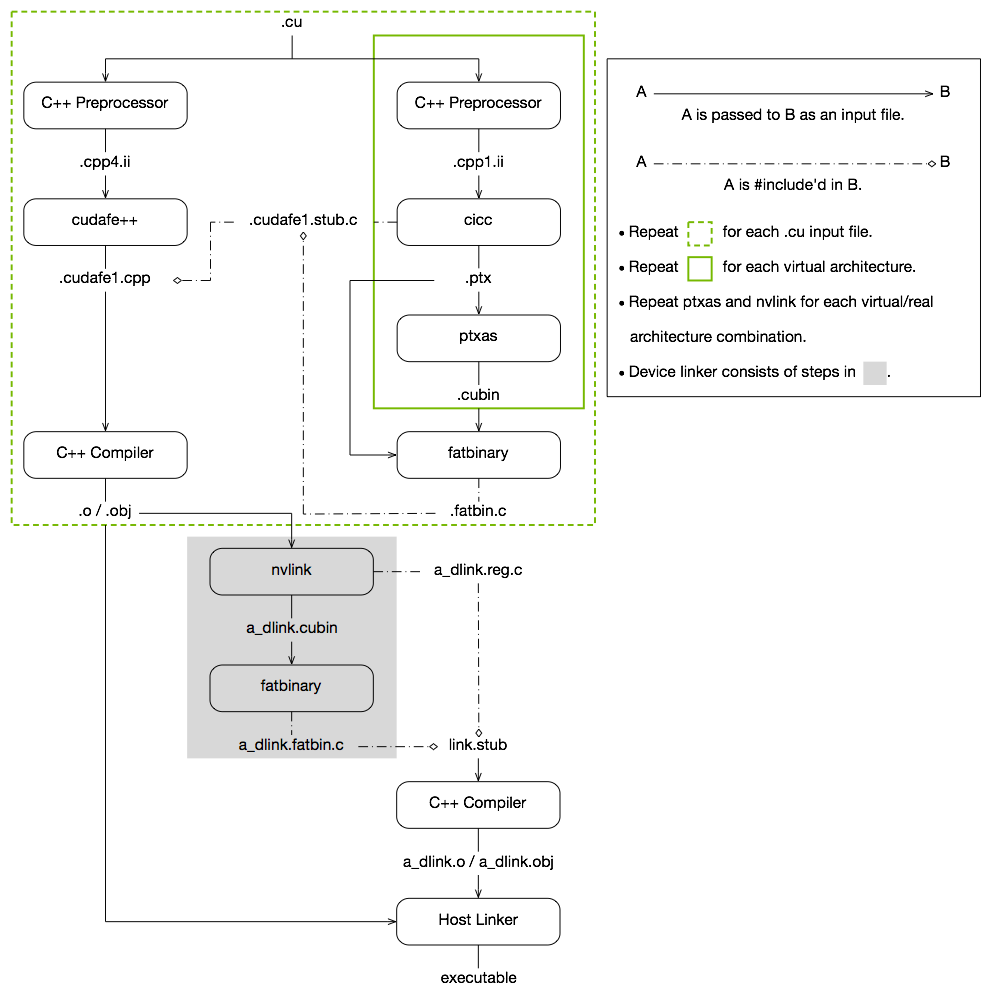
The most intensive part of the process for me was cicc - what I presume stands for 'cuda intermediate cpp compiler'. The surprising part was that there's a double fan-out. Cmake, by default, uses the MAX_JOBS environment variable (or --parallel j if invoked directly instead of through uv / pip build or scikit-build-core) to control the number of jobs in parallel, but this is just for the top-level driver (nvcc). Nvcc can spawn as many cicc as needed, and these are, unfortunately, the real time and memory hogs. Ideally I'd have some limit of global cicc jobs, but I couldn't find a way to do this (although I tried mocking the binary with a gnu parallel sem but no dice!).
Fortunately, you can limit the number of cicc jobs spawned by a single nvcc processor. Even still, some of these CUTLASS files cause cicc to take a long time - most files took many minutes (sometimes tens of minutes) to compile and, in the worst case, over 20gb of ram. Even so, compiling still took all night!
Fixing ccache
Compiling can take all night! You're only making changes to a couple of files at a time, so you'd like to only incrementally recompile. However, this is complicated if you're changing build flags or otherwise need to change your build process. To get around this, you'd use ccache. Read the documentation for details, but the gist is it globally caches the output of the compiler given identical flags / contents.
Unfortunately, I wasted a few nights initially with cache misses! This problem was exacerbated by uv build not outputting the comamnds that I asked it to one, but when I was later debugging compile errors the full compile command for each file got dumped, and I noticed some garbled temp paths in the compile command.
I realized, in order for ccache to have the same build commands, you must include --no-build-isolation in the uv build command! This will remove the temp build environments and lead to the same compile commands.
There's probably a way to get ccache to work (or to switch to bazel, google's build system) but this worked for me.
Before no build isolation:
/usr/bin/ccache /usr/local/cuda/bin/nvcc -forward-unknown-to-host-compiler -DFLASHATTENTION_DISABLE_BACKWARD -DFLASHATTENTION_DISABLE_DROPOUT -DFLASHATTENTION_DISABLE_UNEVEN_K -DPy_LIMITED_API=0x03090000 -DUSE_C10D_GLOO -DUSE_C10D_NCCL -DUSE_DISTRIBUTED -DUSE_IBVERBS -DUSE_RPC -DUSE_TENSORPIPE -Dcommon_ops_EXPORTS -I/home/jack/code/llm/sglang/sgl-kernel/include -I/home/jack/code/llm/sglang/sgl-kernel/csrc -I/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-cutlass-src/include -I/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-cutlass-src/tools/util/include -I/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-flashinfer-src/include -I/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-flashinfer-src/csrc -I/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-mscclpp-src/include -I/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-cutlass-src/examples/77_blackwell_fmha -I/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-cutlass-src/examples/common -I/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-flash-attention-src/csrc/flash_attn/src -isystem /usr/include/python3.12 -isystem /home/jack/.cache/uv/builds-v0/.tmpA67WLH/lib/python3.12/site-packages/torch/include -isystem /home/jack/.cache/uv/builds-v0/.tmpA67WLH/lib/python3.12/site-packages/torch/include/torch/csrc/api/include -isystem /usr/local/cuda/targets/x86_64-linux/include -isystem /usr/local/cuda/targets/x86_64-linux/include/nvtx3 --compiler-options -fdebug-prefix-map='/home/jack'=. --objdir-as-tempdir -DONNX_NAMESPACE=onnx_c2 -Xcudafe --diag_suppress=cc_clobber_ignored,--diag_suppress=field_without_dll_interface,--diag_suppress=base_class_has_different_dll_interface,--diag_suppress=dll_interface_conflict_none_assumed,--diag_suppress=dll_interface_conflict_dllexport_assumed,--diag_suppress=bad_friend_decl --expt-relaxed-constexpr --expt-extended-lambda -D_GLIBCXX_USE_CXX11_ABI=1 -O3 -DNDEBUG -std=c++17 -Xcompiler=-fPIC -DNDEBUG -DOPERATOR_NAMESPACE=sgl-kernel -O3 -Xcompiler -fPIC -gencode=arch=compute_90,code=sm_90 -std=c++17 -DFLASHINFER_ENABLE_F16 -DCUTE_USE_PACKED_TUPLE=1 -DCUTLASS_ENABLE_TENSOR_CORE_MMA=1 -DCUTLASS_VERSIONS_GENERATED -DCUTLASS_TEST_LEVEL=0 -DCUTLASS_TEST_ENABLE_CACHED_RESULTS=1 -DCUTLASS_DEBUG_TRACE_LEVEL=0 --expt-relaxed-constexpr --expt-extended-lambda --threads=8 -Xcompiler=-Wconversion -Xcompiler=-fno-strict-aliasing -gencode=arch=compute_120,code=sm_120 -DFLASHINFER_ENABLE_BF16 -DFLASHINFER_ENABLE_FP8 -DFLASHINFER_ENABLE_FP8_E4M3 -DFLASHINFER_ENABLE_FP8_E5M2 -DENABLE_NVFP4=1 -D_GLIBCXX_USE_CXX11_ABI=1 -MD -MT CMakeFiles/common_ops.dir/csrc/gemm/nvfp4_scaled_mm_kernels.cu.o -MF CMakeFiles/common_ops.dir/csrc/gemm/nvfp4_scaled_mm_kernels.cu.o.d -x cu -c /home/jack/code/llm/sglang/sgl-kernel/csrc/gemm/nvfp4_scaled_mm_kernels.cu -o CMakeFiles/common_ops.dir/csrc/gemm/nvfp4_scaled_mm_kernels.cu.o
after:
/usr/bin/ccache /usr/local/cuda/bin/nvcc -forward-unknown-to-host-compiler -DFLASHATTENTION_DISABLE_BACKWARD -DFLASHATTENTION_DISABLE_DROPOUT -DFLASHATTENTION_DISABLE_UNEVEN_K -DPy_LIMITED_API=0x03090000 -DUSE_C10D_GLOO -DUSE_C10D_NCCL -DUSE_DISTRIBUTED -DUSE_IBVERBS -DUSE_RPC -DUSE_TENSORPIPE -Dcommon_ops_EXPORTS -I/home/jack/code/llm/sglang/sgl-kernel/include -I/home/jack/code/llm/sglang/sgl-kernel/csrc -I/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-cutlass-src/include -I/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-cutlass-src/tools/util/include -I/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-flashinfer-src/include -I/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-flashinfer-src/csrc -I/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-mscclpp-src/include -I/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-cutlass-src/examples/77_blackwell_fmha -I/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-cutlass-src/examples/common -I/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-flash-attention-src/csrc/flash_attn/src -isystem /usr/include/python3.12 -isystem /home/jack/code/llm/sglang/.venv/lib/python3.12/site-packages/torch/include -isystem /home/jack/code/llm/sglang/.venv/lib/python3.12/site-packages/torch/include/torch/csrc/api/include -isystem /usr/local/cuda/targets/x86_64-linux/include -isystem /usr/local/cuda/targets/x86_64-linux/include/nvtx3 --compiler-options -fdebug-prefix-map='/home/jack'=. --objdir-as-tempdir -DONNX_NAMESPACE=onnx_c2 -Xcudafe --diag_suppress=cc_clobber_ignored,--diag_suppress=field_without_dll_interface,--diag_suppress=base_class_has_different_dll_interface,--diag_suppress=dll_interface_conflict_none_assumed,--diag_suppress=dll_interface_conflict_dllexport_assumed,--diag_suppress=bad_friend_decl --expt-relaxed-constexpr --expt-extended-lambda -D_GLIBCXX_USE_CXX11_ABI=1 -O3 -DNDEBUG -std=c++17 -Xcompiler=-fPIC -DNDEBUG -DOPERATOR_NAMESPACE=sgl-kernel -O3 -Xcompiler -fPIC -gencode=arch=compute_90,code=sm_90 -std=c++17 -DFLASHINFER_ENABLE_F16 -DCUTE_USE_PACKED_TUPLE=1 -DCUTLASS_ENABLE_TENSOR_CORE_MMA=1 -DCUTLASS_VERSIONS_GENERATED -DCUTLASS_TEST_LEVEL=0 -DCUTLASS_TEST_ENABLE_CACHED_RESULTS=1 -DCUTLASS_DEBUG_TRACE_LEVEL=0 --expt-relaxed-constexpr --expt-extended-lambda --threads=8 -Xcompiler=-Wconversion -Xcompiler=-fno-strict-aliasing -gencode=arch=compute_120,code=sm_120 -DFLASHINFER_ENABLE_BF16 -DFLASHINFER_ENABLE_FP8 -DFLASHINFER_ENABLE_FP8_E4M3 -DFLASHINFER_ENABLE_FP8_E5M2 -DENABLE_NVFP4=1 -D_GLIBCXX_USE_CXX11_ABI=1 -MD -MT CMakeFiles/common_ops.dir/csrc/gemm/nvfp4_scaled_mm_kernels.cu.o -MF CMakeFiles/common_ops.dir/csrc/gemm/nvfp4_scaled_mm_kernels.cu.o.d -x cu -c /home/jack/code/llm/sglang/sgl-kernel/csrc/gemm/nvfp4_scaled_mm_kernels.cu -o CMakeFiles/common_ops.dir/csrc/gemm/nvfp4_scaled_mm_kernels.cu.o
This scrolls rather poorly on my blog so I'll give up the game: the key difference is:
- -isystem /home/jack/.cache/uv/builds-v0/.tmpA67WLH/lib/python3.12/site-packages/torch/include
+ -isystem /home/jack/code/llm/sglang/.venv/lib/python3.12/site-packages/torch/include
Now the paths are venv relative, not temporary build directory relative. These won't change from build to build, so ccache will finally get a cache hit on the contents of the compiling command line.
Note that for a really resilient cmake we'd want to switch to preprocessor mode (worth it because of the large nvcc latency) and remove almost every flag we see here. This works for me for now, though, so I'll keep it as this.
VSCode
Unfortunately, we no longer have nice red squiggly lines whenever we do something wrong in vscode. There's probably a proper way of doing this, but the easy hack is to rely on the common protocol for any coding tool: the compile_commands.json file!
Our final build command looks like this:
export MAX_JOBS=7 && CMAKE_BUILD_PARALLEL_LEVEL=7 uv build --wheel -Cbuild-dir=build -Ccmake.define.CMAKE_CUDA_COMPILER_LAUNCHER=ccache -Ccmake.define.CMAKE_POLICY_VERSION_MINIMUM=3.5 -Ccmake.define.CMAKE_EXPORT_COMPILE_COMMANDS=YES . --no-build-isolation
I can't figure out how to get scikit build to not reconfigure cmake every time, so I directly call cmake --build build --parallel 7 so we can go nice and quick. If we're making individual changes on a single file, we can even just rerun the nvcc call too and skip the cmake overhead.
Post build setup - the full debug loop.
The first thing to do is turn on logging. CUTLASS does this via the macro CUTLASS_DEBUG_TRACE_LEVEL - the higher it is, the more logging we get. Because cpp only has the concept of compile units, we can just turn it on for our single file by adding #define CUTLASS_DEBUG_TRACE_LEVEL 100 to the top of the file - no need for a modification to the build system.
And indeed, this really helps! We can see much more logging, including the attempt to set the smem size:
(sglang) jack@Chimaera:~/code/llm/sglang$ python test_cuda_error_check.py
Calling FP4 GEMM...
_deps/repo-cutlass-src/include/cutlass/gemm/device/gemm_universal_adapter.h:244 workspace_bytes: 0
_deps/repo-cutlass-src/include/cutlass/gemm/device/gemm_universal_adapter.h:312 GemmUniversal::initialize() - workspace 0, stream: null
_deps/repo-cutlass-src/include/cutlass/gemm/kernel/sm100_gemm_tma_warpspecialized.hpp:264 to_underlying_arguments(): Setting persistent grid SM count to 0
_deps/repo-cutlass-src/include/cutlass/gemm/device/gemm_universal_adapter.h:336 Setting smem size to 218112
_deps/repo-cutlass-src/include/cutlass/gemm/device/gemm_universal_adapter.h:343 cudaFuncSetAttribute() returned error: invalid argument
Python exception: ../csrc/gemm/nvfp4_scaled_mm_kernels.cu:221: Error Internal
I suspect that the limits are hardcoded! Our gemm kernel is for sm_100, which corresponds to the datacenter-class B100. Changing the target architecture to sm_120 yields the following trace:
(sglang) jack@Chimaera:~/code/llm/sglang$ python test_cuda_error_check.py
Calling FP4 GEMM...
_deps/repo-cutlass-src/include/cutlass/gemm/device/gemm_universal_adapter.h:244 workspace_bytes: 0
_deps/repo-cutlass-src/include/cutlass/gemm/device/gemm_universal_adapter.h:312 GemmUniversal::initialize() - workspace 0, stream: null
_deps/repo-cutlass-src/include/cutlass/gemm/kernel/sm90_gemm_tma_warpspecialized_cooperative.hpp:201 to_underlying_arguments():
_deps/repo-cutlass-src/include/cutlass/gemm/kernel/sm90_gemm_tma_warpspecialized_cooperative.hpp:214 WARNING: Arguments do not include a valid SM count.
For optimal performance, populate the arguments KernelHardwareInfo struct with the SM count.
_deps/repo-cutlass-src/include/cutlass/gemm/kernel/sm90_gemm_tma_warpspecialized_cooperative.hpp:218 to_underlying_arguments(): Setting persistent grid SM count to 170
_deps/repo-cutlass-src/include/cutlass/gemm/kernel/sm90_gemm_tma_warpspecialized_cooperative.hpp:224 WARNING: Arguments do not include a valid max cluster count.
For optimal performance, populate the arguments KernelHardwareInfo struct with the max_active_clusters.
_deps/repo-cutlass-src/include/cutlass/gemm/device/gemm_universal_adapter.h:336 Setting smem size to 88064
_deps/repo-cutlass-src/include/cutlass/gemm/device/gemm_universal_adapter.h:343 cudaFuncSetAttribute() returned error: invalid resource handle
Python exception: ../csrc/gemm/nvfp4_scaled_mm_kernels.cu:221: Error Internal
We obviously don't want to clobber the exissting kernel long-term, so it looks like we'll need a sm_120 specific kernel, but this should solve our smem size issue! Unfortunately, we now have a less understandable error: an invalid resource handle.
The concerned attribute call is here. There's only three arguments. One is a constant, one is a size (which we already knows yields invalid argument if it's too large, so solving it should mean this is no longer a problem), and the last one is a pointer to the kernel. Therefore, the problem is that the kernel is invalid - perhaps it was never registered? But why? How?
Kernel???
All software engineering is the same. You do a ton of builds, realize that something is incomplete in your mental model of reality, get frustrated, and then binary search over the size of the problem.
Our next step is to make a standalone cutlass kernel with no pytorch dependencies so we can iterate on it without having to iterate (and worry about) interference from the whole sgl-kernel. Here's the one I used:
/* Copyright 2025 SGLang Team. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#define CUTLASS_DEBUG_TRACE_LEVEL 100
// #define __CUDA_ARCH__ 1200
// #define __CUDA_ARCH_FEAT_SM120_ALL 1
#include <iostream>
#include <stdexcept>
#include <vector>
// CUDA Runtime Headers
#include <cuda_runtime.h>
// CUTLASS Headers
#include "cutlass/cutlass.h"
#include "cutlass/gemm/device/gemm_universal_adapter.h"
#include "cutlass/gemm/kernel/gemm_universal.hpp"
#include "cutlass/gemm/collective/collective_builder.hpp"
#include "cutlass/epilogue/collective/collective_builder.hpp"
#include "cutlass/util/packed_stride.hpp"
// --- Helper Macros (No PyTorch) ---
#define CUDA_CHECK(call) \
do { \
cudaError_t err = call; \
if (err != cudaSuccess) { \
std::cerr << "CUDA Error in " << #call << " at " << __FILE__ << ":" \
<< __LINE__ << ": " << cudaGetErrorString(err) << std::endl; \
throw std::runtime_error(cudaGetErrorString(err)); \
} \
} while (0)
#define CUTLASS_CHECK(status) \
do { \
cutlass::Status error = status; \
if (error != cutlass::Status::kSuccess) { \
std::cerr << "CUTLASS Error: " << cutlassGetStatusString(error) << " at " \
<< __FILE__ << ":" << __LINE__ << std::endl; \
throw std::runtime_error(cutlassGetStatusString(error)); \
} \
} while (0)
using namespace cute;
// Kernel Perf config (remains the same)
template <typename T> struct KernelTraits;
template <> struct KernelTraits<float> {
using MmaTileShape = Shape<_128, _128, _128>;
using ClusterShape = Shape<_1, _1, _1>;
using PerSmTileShape_MNK = Shape<_128, _128, _128>;
};
template <> struct KernelTraits<cutlass::half_t> {
using MmaTileShape = Shape<_128, _128, _128>;
using ClusterShape = Shape<_1, _1, _1>;
using PerSmTileShape_MNK = Shape<_128, _128, _128>;
};
template <typename T>
struct Fp4GemmSm100 {
// A matrix configuration
using ElementA = cutlass::nv_float4_t<cutlass::float_e2m1_t>;
using LayoutATag = cutlass::layout::RowMajor;
static constexpr int AlignmentA = 32;
// B matrix configuration
using ElementB = cutlass::nv_float4_t<cutlass::float_e2m1_t>;
using LayoutBTag = cutlass::layout::ColumnMajor;
static constexpr int AlignmentB = 32;
// C/D matrix configuration
using ElementD = T;
using ElementC = T;
using LayoutCTag = cutlass::layout::RowMajor;
using LayoutDTag = cutlass::layout::RowMajor;
static constexpr int AlignmentD = 128 / cutlass::sizeof_bits<ElementD>::value;
static constexpr int AlignmentC = 128 / cutlass::sizeof_bits<ElementC>::value;
// Kernel functional config
using ElementAccumulator = float;
using ArchTag = cutlass::arch::Sm120;
using OperatorClass = cutlass::arch::OpClassBlockScaledTensorOp;
// Kernel Perf config
using MmaTileShape = typename KernelTraits<T>::MmaTileShape;
using ClusterShape = typename KernelTraits<T>::ClusterShape;
using PerSmTileShape_MNK = typename KernelTraits<T>::PerSmTileShape_MNK;
using CollectiveEpilogue = typename cutlass::epilogue::collective::CollectiveBuilder<
ArchTag,
OperatorClass,
PerSmTileShape_MNK,
ClusterShape,
cutlass::epilogue::collective::EpilogueTileAuto,
ElementAccumulator,
ElementAccumulator,
ElementC,
LayoutCTag,
AlignmentC,
ElementD,
LayoutDTag,
AlignmentD,
cutlass::epilogue::collective::EpilogueScheduleAuto
>::CollectiveOp;
using CollectiveMainloop = typename cutlass::gemm::collective::CollectiveBuilder<
ArchTag,
OperatorClass,
ElementA,
LayoutATag,
AlignmentA,
ElementB,
LayoutBTag,
AlignmentB,
ElementAccumulator,
MmaTileShape,
ClusterShape,
cutlass::gemm::collective::StageCountAutoCarveout<static_cast<int>(
sizeof(typename CollectiveEpilogue::SharedStorage))>,
cutlass::gemm::collective::KernelScheduleAuto
>::CollectiveOp;
using GemmKernel =
cutlass::gemm::kernel::GemmUniversal<Shape<int, int, int, int>, CollectiveMainloop, CollectiveEpilogue, void>;
using Gemm = cutlass::gemm::device::GemmUniversalAdapter<GemmKernel>;
using StrideA = typename Gemm::GemmKernel::StrideA;
using LayoutA = decltype(cute::make_layout(make_shape(0, 0, 0), StrideA{}));
using LayoutSFA = typename Gemm::GemmKernel::CollectiveMainloop::LayoutSFA;
using StrideB = typename Gemm::GemmKernel::StrideB;
using LayoutB = decltype(cute::make_layout(make_shape(0, 0, 0), StrideB{}));
using LayoutSFB = typename Gemm::GemmKernel::CollectiveMainloop::LayoutSFB;
using StrideC = typename Gemm::GemmKernel::StrideC;
using LayoutC = decltype(cute::make_layout(make_shape(0, 0, 0), StrideC{}));
using StrideD = typename Gemm::GemmKernel::StrideD;
using LayoutD = decltype(cute::make_layout(make_shape(0, 0, 0), StrideD{}));
static_assert(GemmKernel::SharedStorageSize <= cutlass::arch::sm120_smem_capacity_bytes,
"SMEM usage exceeded SM120 capacity.");
};
// --- Standalone Run Function (No PyTorch) ---
template <typename T>
void runGemm(int M, int N, int K,
void* d_A, void* d_B, void* d_C, void* d_D,
void* d_A_scale, void* d_B_scale,
float alpha) {
using GemmOp = Fp4GemmSm100<T>;
using ElementA = typename GemmOp::Gemm::ElementA;
using ElementB = typename GemmOp::Gemm::ElementB;
using ElementSFA = cutlass::float_ue4m3_t;
using ElementSFB = cutlass::float_ue4m3_t;
using ElementD = typename GemmOp::Gemm::ElementD;
using ElementCompute = float;
using StrideA = typename GemmOp::StrideA;
using StrideB = typename GemmOp::StrideB;
using StrideD = typename GemmOp::StrideD;
using Sm1xxBlkScaledConfig = typename GemmOp::Gemm::GemmKernel::CollectiveMainloop::Sm1xxBlkScaledConfig;
int m = static_cast<int>(M);
int n = static_cast<int>(N);
int k = static_cast<int>(K);
auto stride_A = cutlass::make_cute_packed_stride(StrideA{}, {m, k, 1});
auto stride_B = cutlass::make_cute_packed_stride(StrideB{}, {n, k, 1});
auto stride_D = cutlass::make_cute_packed_stride(StrideD{}, {m, n, 1});
auto layout_SFA = Sm1xxBlkScaledConfig::tile_atom_to_shape_SFA(cute::make_shape(m, n, k, 1));
auto layout_SFB = Sm1xxBlkScaledConfig::tile_atom_to_shape_SFB(cute::make_shape(m, n, k, 1));
typename GemmOp::Gemm::Arguments arguments{
cutlass::gemm::GemmUniversalMode::kGemm,
{M, N, K, 1},
// {static_cast<typename GemmOp::ElementA*>(d_A), K},
// {static_cast<typename GemmOp::ElementB*>(d_B), K},
// {static_cast<T*>(d_C), N},
// {static_cast<T*>(d_D), N},
// {alpha, 0.f}, // Epilogue: C = alpha * A*B + beta*C. Set beta=0 for simplicity.
// -1 // split-k slices
{
static_cast<ElementA const*>(d_A),
stride_A,
static_cast<ElementB const*>(d_B),
stride_B,
static_cast<ElementSFA const*>(d_A_scale),
layout_SFA,
static_cast<ElementSFB const*>(d_B_scale),
layout_SFB
},
{ // Epilogue arguments
{}, // epilogue.thread
static_cast<ElementD const*>(d_D),
stride_D,
static_cast<ElementD*>(d_D),
stride_D
}
};
typename GemmOp::Gemm gemm;
size_t workspace_size = GemmOp::Gemm::get_workspace_size(arguments);
void* workspace = nullptr;
if (workspace_size > 0) {
CUDA_CHECK(cudaMalloc(&workspace, workspace_size));
}
std::cout << "Initializing CUTLASS GEMM..." << std::endl;
CUTLASS_CHECK(gemm.initialize(arguments, workspace));
std::cout << "Running CUTLASS GEMM..." << std::endl;
CUTLASS_CHECK(gemm.run());
std::cout << "CUTLASS GEMM Finished." << std::endl;
if (workspace) {
cudaFree(workspace);
}
}
// --- Main Entry Point ---
int main() {
try {
// Problem definition
int M = 1024;
int N = 4096;
int K = 4096;
float alpha = 1.0f;
using OutputType = float; // Testing with FP32 output
// FP4 uses 4 bits. Two elements fit in one byte.
size_t size_A_bytes = M * K / 2;
size_t size_B_bytes = K * N / 2;
size_t size_C_bytes = M * N * sizeof(OutputType);
size_t size_D_bytes = M * N * sizeof(OutputType);
// Placeholder for scales, not used in this simplified GEMM but allocating them
// to match the original function's structure.
size_t size_A_scale_bytes = M * K / 16 * sizeof(float);
size_t size_B_scale_bytes = K * N / 16 * sizeof(float);
void *d_A, *d_B, *d_C, *d_D, *d_A_scale, *d_B_scale;
std::cout << "Allocating device memory..." << std::endl;
CUDA_CHECK(cudaMalloc(&d_A, size_A_bytes));
CUDA_CHECK(cudaMalloc(&d_B, size_B_bytes));
CUDA_CHECK(cudaMalloc(&d_C, size_C_bytes));
CUDA_CHECK(cudaMalloc(&d_D, size_D_bytes));
CUDA_CHECK(cudaMalloc(&d_A_scale, size_A_scale_bytes));
CUDA_CHECK(cudaMalloc(&d_B_scale, size_B_scale_bytes));
// Initialize memory to zero
CUDA_CHECK(cudaMemset(d_A, 0, size_A_bytes));
CUDA_CHECK(cudaMemset(d_B, 0, size_B_bytes));
CUDA_CHECK(cudaMemset(d_C, 0, size_C_bytes));
runGemm<OutputType>(M, N, K, d_A, d_B, d_C, d_D, d_A_scale, d_B_scale, alpha);
CUDA_CHECK(cudaDeviceSynchronize());
std::cout << "Device synchronized successfully." << std::endl;
// Cleanup
CUDA_CHECK(cudaFree(d_A));
CUDA_CHECK(cudaFree(d_B));
CUDA_CHECK(cudaFree(d_C));
CUDA_CHECK(cudaFree(d_D));
CUDA_CHECK(cudaFree(d_A_scale));
CUDA_CHECK(cudaFree(d_B_scale));
std::cout << "\n[SUCCESS] Standalone test finished without errors." << std::endl;
} catch (const std::exception& e) {
std::cerr << "\n[FAILURE] An error occurred: " << e.what() << std::endl;
return 1;
}
return 0;
}
A nice part of extracting the error to a standalone file is we can quickly iterate on the compile command without cmake! Binary searching over the problem, in the case of cpp, includes the flags:
ccache nvcc -std=c++17 -I$(CUTLASS_INCLUDE_DIR) \
-I/home/jack/code/llm/sglang/sgl-kernel/build-old/_deps/repo-flashinfer-src/3rdparty/cutlass/tools/util/include \
-g -G \
-arch=sm_120 \
-gencode=arch=compute_120,code=sm_120 \
$< -o $@
With our standalone kernel, we get the same error with our test script! Joy.
With nothing left to adjust, I start messing around with various compiler flags. A more experienced developer would probably go into the assembly and cuda gdb at this point, but I'm not experienced enough to breeze around the binary, so instead I play the flag lottery and get lucky without too much time.
If you remember, cuda uses a cpp compiler as part of the nvcc process. The two large cpp compilers are clang++ and gcc++. By default, nvcc uses gcc++. What if we switch to clang++?
We switch the cuda cpp compiler to clang++ away from gcc to see if we get any difference. Surprisingly, this leads to a success! No invalid handle! With just adding -ccbin clang++-19.
The test still fails, but the crash is much different:
src/include/cutlass/gemm/device/gemm_universal_adapter.h:356 Setting smem size to 100352
Running CUTLASS GEMM...
/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-cutlass-src/include/cutlass/gemm/device/gemm_universal_adapter.h:392 GemmUniversal::run()
/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-cutlass-src/include/cutlass/gemm/device/gemm_universal_adapter.h:403 GemmUniversal::run: Use extended launch API
/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-cutlass-src/include/cutlass/gemm/device/gemm_universal_adapter.h:499 GemmUniversal::run: Launching static 1x1x1 kernel
/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-cutlass-src/include/cutlass/kernel_launch.h:84 cutlass::kernel_launch
/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-cutlass-src/include/cutlass/kernel_launch.h:89 cutlass::kernel_launch: No PDL
/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-cutlass-src/include/cutlass/kernel_launch.h:130 cutlass::kernel_launch: cudaGetLastError reports success
/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-cutlass-src/include/cutlass/gemm/device/gemm_universal_adapter.h:507 GemmUniversal::run: cutlass::kernel_launch reports success
/home/jack/code/llm/sglang/sgl-kernel/build/_deps/repo-cutlass-src/include/cutlass/gemm/device/gemm_universal_adapter.h:573 GemmUniversal::run: cudaGetLastError reports success
CUTLASS GEMM Finished.
ERROR : Arch conditional MMA instruction used without targeting appropriate compute capability. Aborting.
ERROR : Arch conditional MMA instruction used without targeting appropriate compute capability. Aborting.
<repeated ad infinitum>
I try for several different versions of clang and gcc, and there's a clear pattern: gcc gives us an invalid handle error on a cuda API call, and clang passes that check but fails later.
The good news is that the clang failure gives us a lot of information to work on: there's an invalid instruction in the kernel. A hypothesis now is the kernel is invalid because we aren't targeting the right compute capability, and the gcc-compiled launcher does some additional checks and rules out the handle, thus causing us to fail.
Interlude: What is a fat binary?
Theory: Why are there architecture-specific flags for GPUs
When you compile CUDA code, you're actually generating code for two very different processors: your CPU (the host) and your GPU (the device). The CPU code generation is fairly straightforward and follows generation like every other piece of code compiled by cc. One of the key pieces of how CPU code is compiled is the assembly. If you're compiling for x86_64 (the most common desktop CPU architecture), you can run on any cpu that supports the x86_64 instruction set (again, most desktops). However! Desktop CPUs have improved since the architecture first came out, with new instructions and features. I can still run my old code on my CPU, though. What gives?
The answer is most CPU code is compiled targeting the base instruction set. This includes most of the instructions that are available on all CPUs. However, suppose you have a modern instruction, such as AVX-512-VNNI, a new instruction meant to speed up neural network inference, such as bf16, that's (obviously) not available on older x86_64 CPUs. These instructions do not exist on older CPUs, so a compiler will, by default, not generate them. You have to supply a special flag to the compiler telling it to target a specific extension to the instruction set to enable generation. JITs, such as Chrome's V8, will automatically generate the code depending on the CPU's features (interpreters stay winning).
Most programs still use the maximum compatibility instruction set. However, they still aren't slow because most programs don't need or use these instructions in almost all of the cases: the famous Jim Keller has a good quote (honestly recommend reading the whole interview).
JK: [Arguing about instruction sets] is a very sad story. It's not even a couple of dozen [op-codes] - 80% of core execution is only six instructions - you know, load, store, add, subtract, compare and branch. With those you have pretty much covered it. If you're writing in Perl or something, maybe call and return are more important than compare and branch. But instruction sets only matter a little bit - you can lose 10%, or 20%, [of performance] because you're missing instructions.
For a while we thought variable-length instructions were really hard to decode. But we keep figuring out how to do that. You basically predict where all the instructions are in tables, and once you have good predictors, you can predict that stuff well enough. So fixed-length instructions seem really nice when you're building little baby computers, but if you're building a really big computer, to predict or to figure out where all the instructions are, it isn't dominating the die. So it doesn't matter that much.
When RISC first came out, x86 was half microcode. So if you look at the die, half the chip is a ROM, or maybe a third or something. And the RISC guys could say that there is no ROM on a RISC chip, so we get more performance. But now the ROM is so small, you can't find it. Actually, the adder is so small, you can hardly find it? What limits computer performance today is predictability, and the two big ones are instruction/branch predictability, and data locality.
Now the new predictors are really good at that. They're big - two predictors are way bigger than the adder. That's where you get into the CPU versus GPU (or AI engine) debate. The GPU guys will say ‘look there's no branch predictor because we do everything in parallel’. So the chip has way more adders and subtractors, and that's true if that's the problem you have. But they're crap at running C programs.
I gave away the game a bit at the end there! The reason why CPUs can get away with most programs not needing every latest and greatest instruction set innovation is because most of their time isn't bound by specific logic patterns. Most of their time is bound by the higher level conceptual problem of predicting what the next instruction is going to be. If you (very rarely) want to fork on some specific capability for some case, you can specialize a certain function based on feature flags (or anything else) or dynamically load from a selection of libraries - the key is both approaches suggest that it's a special case rather than the common case to need cutting-edge instructions.
GPUs don't have that! Before you run the program, for most AI-relevant GPU kernels, you can trace more or less the exact sequence of instructions that the GPU will execute for the next however-many-hours it'll take for you to chew through your inference job. Because of this, if your GPU were to say, ship a new instruction that does double the adds in half the time, that'll directly make every program run on the GPU ~400% faster, rather than making some programs ~1% faster. Or, in short, universal binaries because hopelessly outclassed by their specialized counterparts.
The GPU code goes through several stages:
PTX (Parallel Thread Execution): This is NVIDIA's virtual assembly language - think of it as GPU bytecode. It's forward-compatible, meaning PTX compiled for sm_120 will run on sm_130, but potentially without using newer features. cubin: This is the actual machine code for a specific GPU architecture. A cubin compiled for sm_120 will ONLY run on sm_120 GPUs. It's like how x86 assembly won't run on ARM.
Now here's where it gets interesting - what if you want your code to run on multiple GPU architectures? You could:
Ship multiple binaries (annoying) Compile on the user's machine (slow) Use a fat binary!
A fat binary (or "fatbin") is NVIDIA's solution: it bundles multiple cubins and/or PTX code into a single file. When you run your program, the CUDA runtime picks the best match:
my_kernel.fatbin:
├── PTX for compute_120 (virtual architecture)
├── cubin for sm_120 (RTX 5090)
├── cubin for sm_120a (RTX 5090 with special features)
└── cubin for sm_90 (H100)
When you specify multiple -gencode flags like:
-gencode=arch=compute_120,code=sm_120 \
-gencode=arch=compute_120a,code=sm_120a
You're telling nvcc: "Generate PTX for compute capability 120, then compile it to machine code for both sm_120 and sm_120a." This is why our error makes sense now! When we only generated for sm_120, we were missing the sm_120a-specific instructions that FP4 needs. The kernel handle was "invalid" because gcc's runtime checks noticed we were trying to load a kernel that didn't have the right architecture variant. The 'a' suffix typically indicates architecture variants with special features - in our case, likely the FP4 tensor core instructions that only exist on certain SKUs.
Perhaps we need to generate a fat binary with LOTS of compute capabilities? Lets try it out!
pure_cutlass_runner_clang_19: standalone.cu
@echo "Compiling with CUTLASS headers from: $(CUTLASS_INCLUDE_DIR)"
ccache nvcc -std=c++17 -I$(CUTLASS_INCLUDE_DIR) \
-I/home/jack/code/llm/sglang/sgl-kernel/build-old/_deps/repo-flashinfer-src/3rdparty/cutlass/tools/util/include \
-g -G \
-t 20 \
-arch=sm_120a \
-gencode=arch=compute_120,code=sm_120 \
-gencode=arch=compute_120a,code=sm_120a \
-gencode=arch=compute_90,code=sm_90 \
-gencode=arch=compute_90a,code=sm_90a \
-gencode=arch=compute_100,code=sm_100 \
-gencode=arch=compute_100a,code=sm_100a \
-gencode=arch=compute_101,code=sm_101 \
-gencode=arch=compute_101a,code=sm_101a \
$< -o $@
this... takes a long time to compile - I kill it after ptxas doesn't finish overnight.
15701 jack 20 0 23.3G 23.3G 6912 R 100.0 23.3 11h55:42 ptxas -arch sm_120a -m64 -g --dont-merge-basicblocks --return-at-end /tmp/tmpxft_0000391e_00000000-1
Some changes later reveal that -g the debug flag, is the culprit (a github issue says that this used to be true but since got solved - apparently not!). If I ever specify sm_120a as a code gen target, I must not output debug information or ptxas hangs forever.
Some changes into a slimmed down version:
ccache nvcc -std=c++17 -I$(CUTLASS_INCLUDE_DIR) \
-I/home/jack/code/llm/sglang/sgl-kernel/build-old/_deps/repo-flashinfer-src/3rdparty/cutlass/tools/util/include \
-t 20 \
--split-compile 20 \
-ccbin clang++-19 \
-gencode=arch=compute_120,code=sm_120 \
-gencode=arch=compute_120a,code=sm_120a \
Causes it to compile and pass the test!
Ultimately, it seems like the following:
- Having sm_120a as a gencode target and having -g causes ptxas to loop forever.
- Generating for compute_120a is necessary to get the right compute capability.
- GCC causes a failure.
The last one is the most confusing.
Easy enough to fix surgically though in our cmake specification!
bashset(CLANG_NVCC_FLAGS "-ccbin clang++-19")
# List of files that need clang++
set(CLANG_REQUIRED_SOURCES
"csrc/gemm/nvfp4_scaled_mm_kernels.cu"
)
# Apply the flags to the specific source files
set_source_files_properties(
${CLANG_REQUIRED_SOURCES}
PROPERTIES COMPILE_FLAGS "${CLANG_NVCC_FLAGS}"
)
We get our fp4 test passing now!
tests/test_fp4_gemm.py ............ [100%]
======================== 12 passed in 112.35s (0:01:52) ========================
Now, sglang runs our model. Unfortunately, it only outputs gibberish. If I had to guess, there's probably an issue with the scale factor somewhere. vLLM has the same issue - the problem likely lies either in the scale factor that we had trouble setting or in the flashinfer (??? maybe???) code.
Maybe we'll come back to this and try and get e2e working.
Footnotes
There is, of course, more nuance. Read the JAX scaling book. ↩
For a walkthrough, see Fabien's guide on compiler drivers. Note that nvcc calls cc, which means that we have a compiler driver call another compiler driver! It's drivers all the way down. ↩